
分布式锁的抢占过程
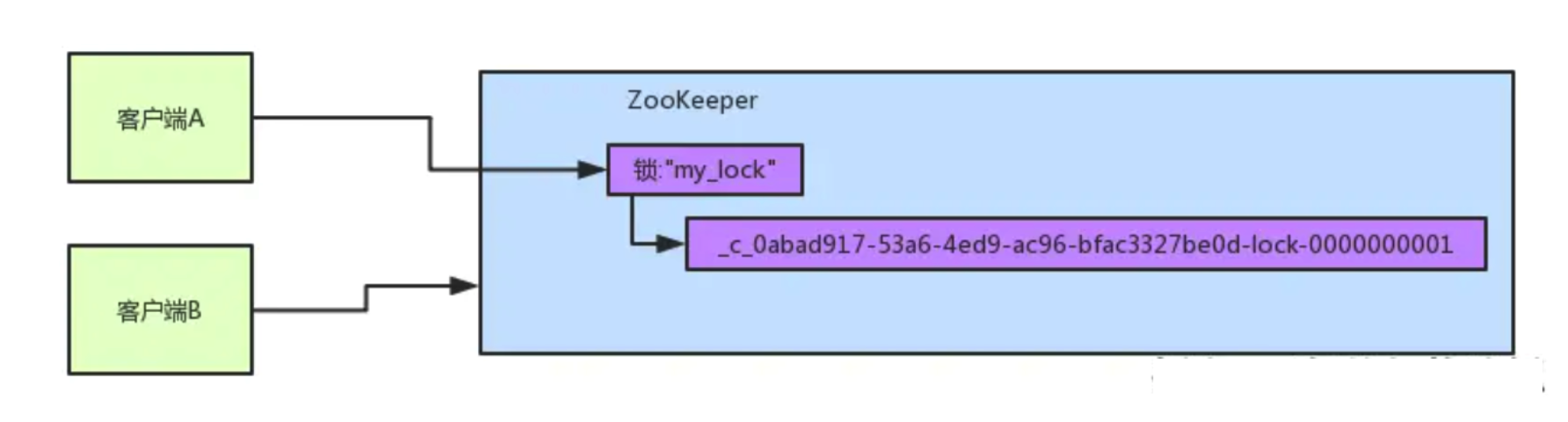
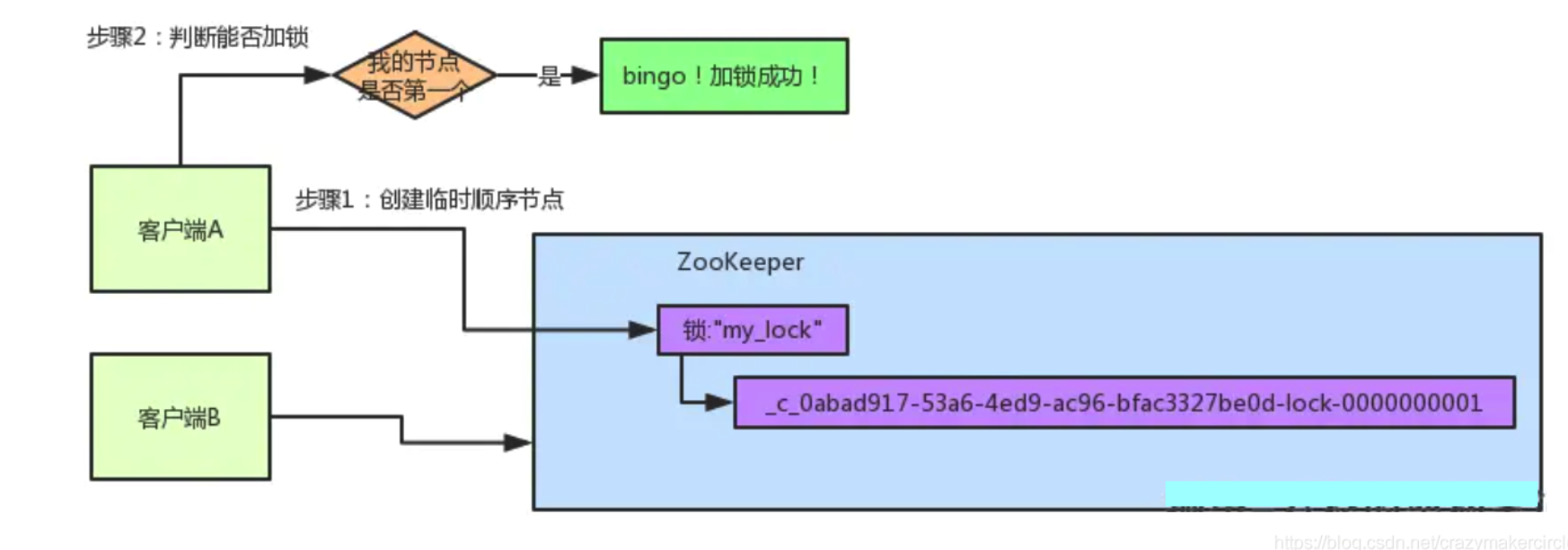
客户端A发起一个加锁请求,先会在你要加锁的node下搞一个临时顺序节点,这一大坨长长的名字都是Curator框架自己生成出来的。
然后,那个最后一个数字是”1”。因为客户端A是第一个发起请求的,所以给他搞出来的顺序节点的序号是”1”。
接着客户端A创建完一个顺序节点。还没完,他会查一下”my_lock”这个锁节点下的所有子节点,并且这些子节点是按照序号排序的,这个时候他大概会拿到这么一个集合:

接着,客户端A会做一个关键性的判断,看自己创建的临时顺序节点是否排在第一个,如果是的话,就进行加锁操作.
因为是第一个创建顺序节点的人,所以就是第一个尝试加分布式锁的人.
客户端B前来排队
客户端A已经加完锁了,客户端B想来加锁,先在my_lock这个锁节点下创建一个临时顺序节点,此时名字会变成类似这个
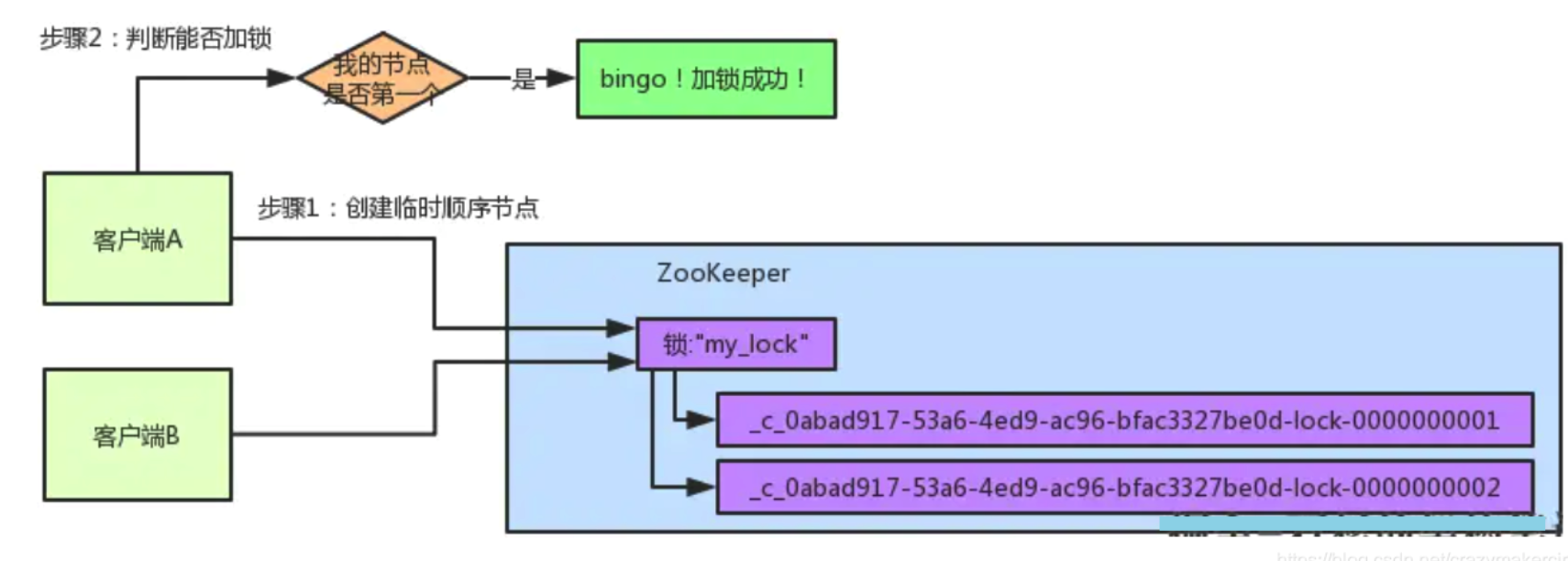
客户端B因为是第二个来创建顺序节点的,所以zk内部会维护序号为”2”。
接着客户端B会走加锁判断逻辑,查询”my_lock”锁节点下的所有子节点,按序号顺序排列,此时他看到的类似于:

同时检查自己创建的顺序节点,是不是集合中的第一个?
明显不是啊,此时第一个是客户端A创建的那个顺序节点,序号为”01”的那个。所以加锁失败!
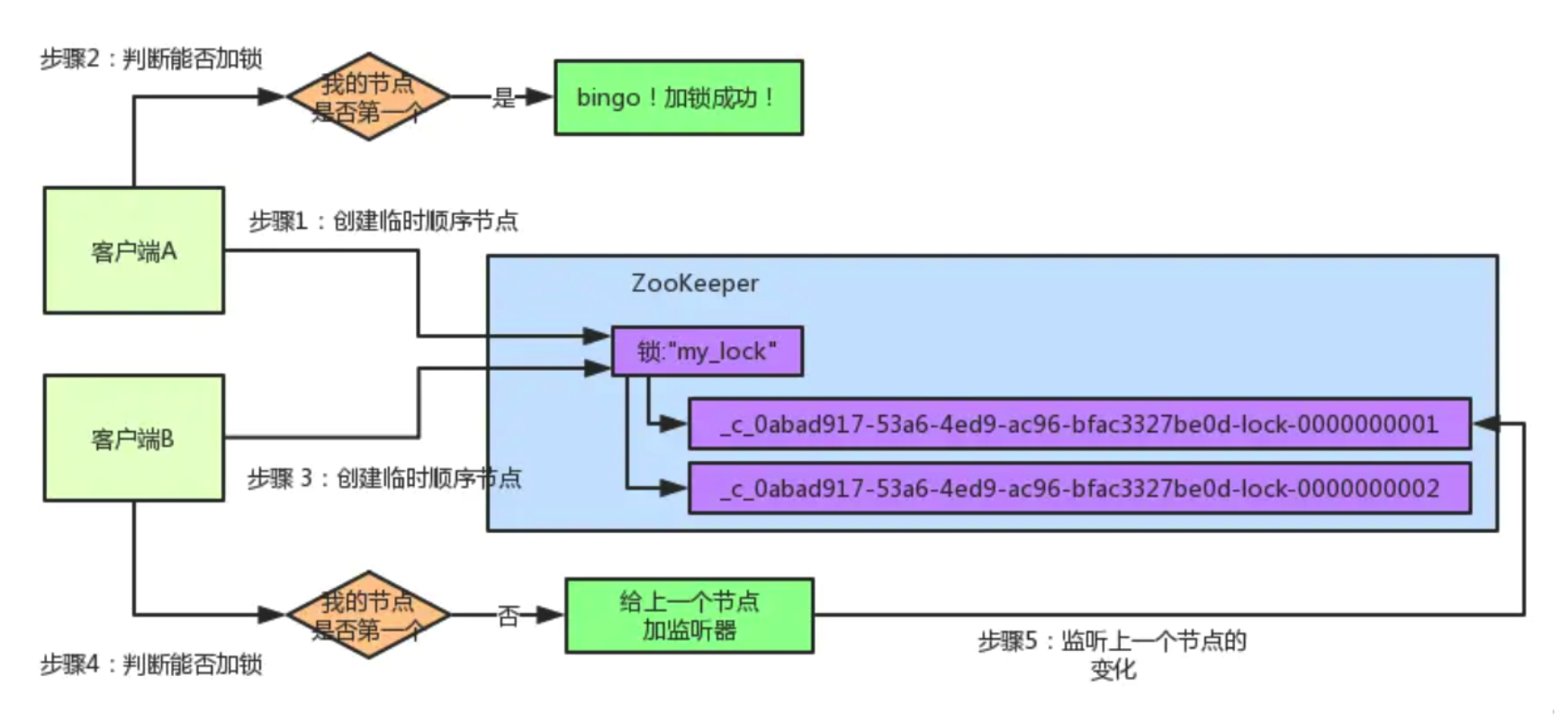
客户端B开启监听客户端A
加锁失败了以后,客户端B就会通过zookeeper的API对他的顺序节点的上一个顺序节点加一个监听器。zookeeper天然就可以实现对某个节点的监听。
客户端B会对排在他前面的那个节点加一个监听器,监听这个节点是否被删除等变化!大家看下面的图。
接着,客户端A加锁之后,可能处理了一些代码逻辑,然后就会释放锁。那么,释放锁是个什么过程呢?
其实很简单,就是把自己在zk里创建的那个顺序节点,也就是001节点会被删除
删除了那个节点之后,zookeeper会负责通知监听这个节点的监听器,也就是客户端B之前加的那个监听器,说:兄弟,你监听的那个节点被删除了,有人释放了锁。
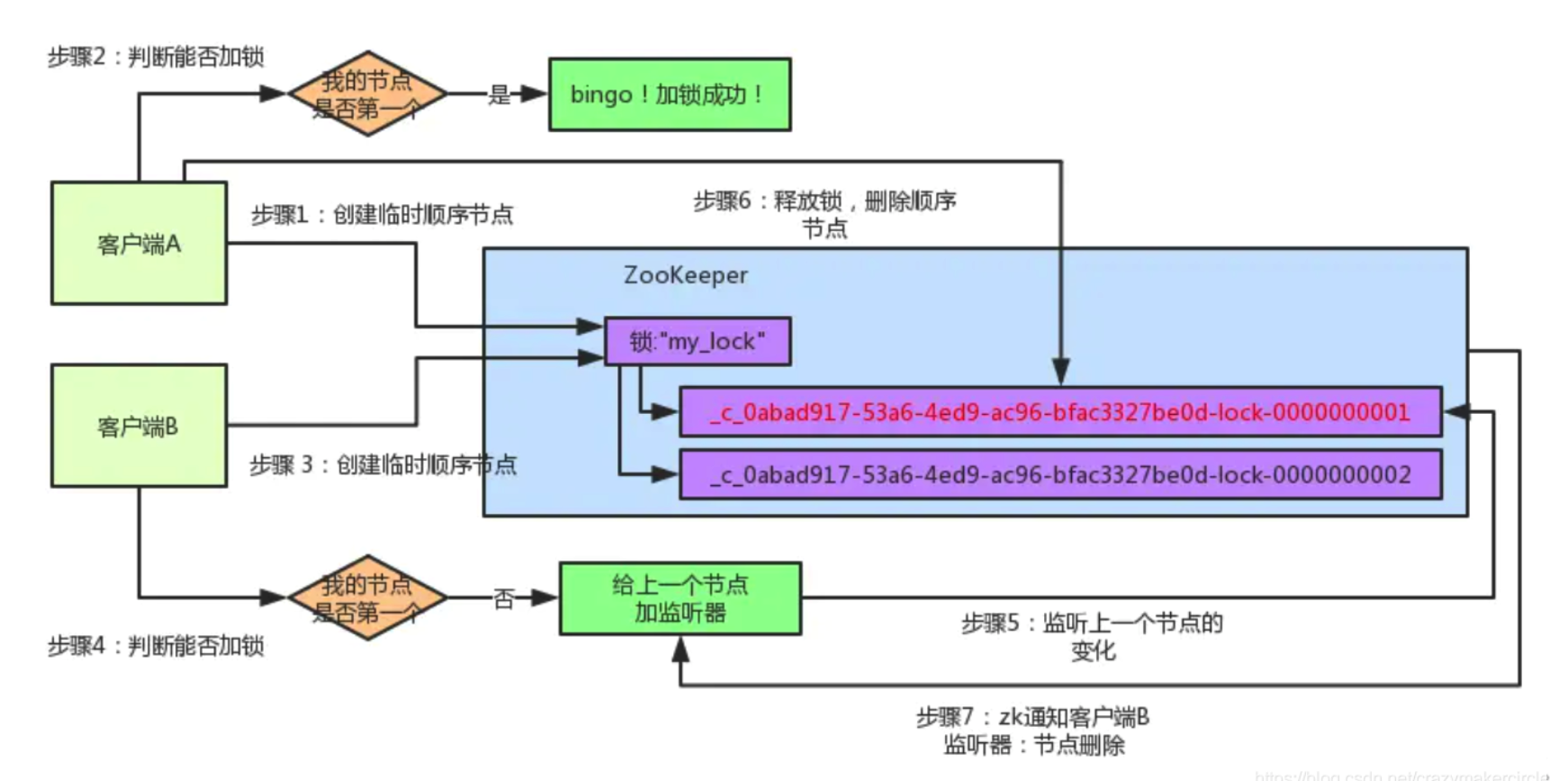
此时客户端B的监听器感知到了上一个顺序节点被删除,也就是排在他之前的某个客户端释放了锁。
此时,就会通知客户端B重新尝试去获取锁,也就是获取”my_lock”节点下的子节点集合,此时为:

集合里此时只有客户端B创建的唯一一个临时顺序节点了.
然后呢,客户端B判断自己居然是集合中的第一个顺序节点,可以加锁了!直接完成加锁,运行后续的业务代码即可,运行完了之后再次释放锁。